Choosing the best schema to improve Google Bigtable performance
Our Personalization feature relies on Google Bigtable, a managed database hosted on Google Cloud Platform. We found that a Bigtable schema change can lead to a 3x performance gain when computing user profiles. We’re going to take you inside our investigation on how we scaled and improved the Bigtable performance, describing key learnings we gathered along the way.
What is Google Bigtable
Bigtable is a distributed storage system for managing structured data. It is designed to scale horizontally. It has been developed internally at Google since 2004 and became publicly available in 2015 as part of Google Cloud Platform.
Bigtable stores the data as a sorted map indexed by a row key, column key, and timestamp:
(row:string, column:string, time:int64) -> []byte
It maintains the data in lexicographical order by the row key, which allows for querying ranges of rows by specifying a prefix. The column key is composed of a family key and a qualifier. Since the data is split by table and family key and stored together in individual tablets (physical hard drives), it imposes some restrictions on the family key: we need to specify the family key along with the table name when creating the table and it is recommended to store elements with the same access patterns under the same family key. Additionally, the documentation recommends having a few family keys (100 at most) only with alphanumeric characters. On the other hand, the qualifier has less constraints and can be created with a row with arbitrary characters.

Capturing and storing user events for Google Bigtable
Back to the use case. As our docs describe, Personalization relies on user events such as page views, clicks, and conversions to build user profiles. These events are sent by our customers through the Insights API and are defined by a type (view, click, conversion), a name (e.g., “homepage”), and an object identifier.
Consider an online marketplace where a user clicked on a black Apple iPhone from the homepage. We receive the following event, where the user_token is a unique, anonymized user identifier generated by Algolia’s customers:
{"app_id": "app","user_token": "24d64a80-8d1c-11e9-bc42-526af7764f64","object_ids": ["af3d4d14-8d1c-11e9-bc42-526af7764f64"],"timestamp": "2019-05-28T00:04:34.000Z","event_type": "click","event_name": "homepage"}
The users who interact with products generate events, from which we build user profiles. A user profile represents a user’s affinities and interests for categories, brands, etc. Concretely, we have implemented a user profile as a key-value structure that consists of filters associated with scores. In our example below, the filter color:Red has a score of 12, which is determined by the amount of implicit interactions of the user with items of color red.
color:Red -> score: 12brand:Apple -> score: 10color:Black -> score: 8brand:Sony -> score: 3brand:Samsung -> score: 2
The scores of the filters in the user profiles are generated according to a strategy that defines the importance of each event (e.g., conversion, view, click) as well as the importance of each filter associated with the event.
At query time, the user profile of a given user is used to boost the most relevant items with matching filters. This provides a seamless personalized experience to our users.
Building real-time user profiles
Speed matters and we aim to provide a real-time personalized experience to our users. Furthermore, when our customers make updates to their personalization strategy, we want to update all the user profiles with the new strategy as fast as possible.
This has led us to build two separate pipelines to compute and update the user profiles:
- A streaming pipeline that computes user profiles when we receive events
- A batching pipeline that re-computes all the user profiles following a strategy update
The pipelines are deployed on a Kubernetes cluster hosted on Google Cloud Platform. We store the events sent by our customers in Bigtable, as it is able to handle high read and write throughput for large amounts of data. Used as a multi-tenant system, Bigtable’s schema provides a strong guarantee to isolate the data of each customer. The figure below depicts a high-level architecture of both personalization pipelines.
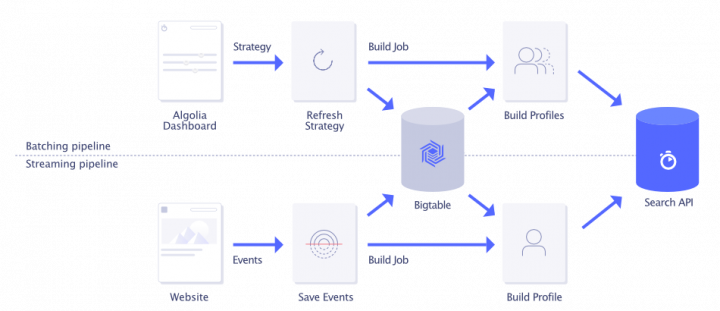
Scaling the batching pipeline
As more customers use personalized search, we need to handle an increasing load when computing the user profiles. Specifically, we need to make sure that the batching pipeline will scale. As an example, if a customer sends 10 million events per day on average over the retention period of 90 days, the pipeline would have to retrieve and process a total of 900 million events when the strategy gets updated.
Since the performance of the pipeline mainly depends on the read throughput of Bigtable, we want to investigate the performance impact of different table schemas to store the events in Bigtable, and to evaluate the impact of the number of events to retrieve on the processing duration of the pipeline.
Our Bigtable schema
Designing a schema for our personalization Bigtable consisted in determining the format of the row key and the structure of the row value.
Row key. The row key design is specific to the use cases and the access patterns. As we have explained above, we need to access all the events sent by one of our customers or all the events sent by one of their users. As such, reads are more important than writes, as we need to retrieve all the events of a user each time we build their profile. In order to perform efficient scans on blocks of sorted keys, related rows need to be near each other. As such, we designed the following schema that allows for a sequential scan of a customer (from their identifier, app_id) and their users (from their identifier, user_token):
app_id,user_token,YYYY-mm-DDTHH:MM:SS.SSSZ
Row value. The row value is composed of a column key (with a family key and qualifier) and a column value. The value of a row will store an event that is composed of the following:
- Event type (conversion, click, view)
- Event name (user defined, e.g., homepage)
- List of filters (of the format
filter_name,filter_operator,filter_value)
Narrow and wide row values
There are different ways to structure the row value schema. One schema consists in storing the full data structure in the value of the row. This results in a tall and narrow table that has a small number of events per row with a single family name and qualifier per row. On the other hand, one may leverage multiple families and qualifiers within the same row to hierarchically structure the value. This results in a short and wide table with a large number of events per row.

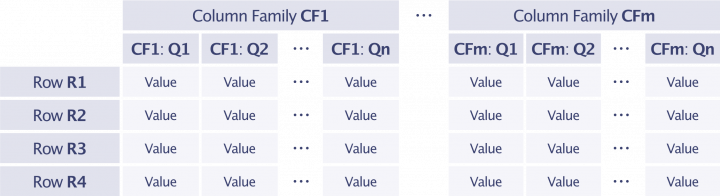
Narrow schema
Since the different event types are fixed and composed of alphabetic characters, they are good candidates to be a family key. Because it is user defined and has high cardinality, the event name cannot be used as a family key; however, it can be used as a qualifier. The list of filter counts can then be used as a value and encoded in a JSON format, for instance to have readable values when reading the rows of the table with cbt, the official command line tool to interact with Bigtable.
The resulting schema is the following:
row: app_id,user_token,timestampfamily key: event_typequalifier: event_namevalue: [filter_counts]
This is the schema that we currently use to store events.
As a result, the following two events are stored in the table as follows (note: we have shortened the timestamps):
[{"app_id": "app","object_ids": ["black-apple-iphone"],"user_token": "user1","timestamp": "2019-05-28","event_type": "click","event_name": "homepage"},{"app_id": "app","object_ids": ["red-samsung-s11"],"user_token": "user2","timestamp": "2019-05-29","event_type": "click","event_name": "search"}]
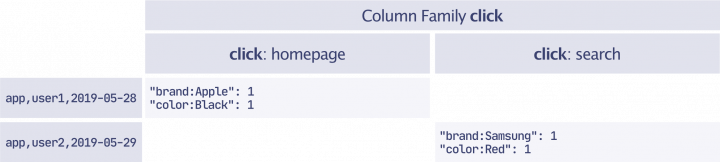
Wide schema
With the narrow schema defined above, we need to retrieve all the filters associated with each event to compute the user profile. However, we compute a user profile from the filters defined in the strategy, which is a subset of the filters contained in the events. Having to discard some filters from the events in our container creates a throughput and memory overhead.
Instead, the wide schema uses the family and qualifiers to create a wide row format, and filters the event filter names at server side. Since the filters are defined by their name in the strategy, we index the row value by the filter name with the qualifier. Given the limitations of the family key in terms of format and number, we can only use the qualifier to index the row value by the filter name. As a result, we encode the tuple (event_type, event_name, filter_name) as the qualifier in CSV format. The family names are limited to 100 and need to be defined in advance and thus cannot be customer-defined values. Instead, we use a single letter, e, as the family key in order to minimize its overhead when transmitting the full row over the network. Note that the family key can have a versioning semantic, which can be useful to migrate the data from one family to another. The row value is then an array of the (filter_operator, filter_value) counts. The qualifiers of a row are then queried using an interleaved filter based on the filters present in the strategy.
These considerations led to design the following wide schema:
row: app_id,user_token,timestampfamily key: equalifier: CSV(event_type, event_name, filter_name)value: [(filter_operator,filter_value)]
As an example, if we take the two events given above, then we have the following table:

Choice of Bigtable schema scales performance
With a few applications that are sending events, we decided to simulate real-world events in order to compare the performance of the two schemas. We generated different application profiles, from a few users sending millions of daily events to millions of users sending a few events. We created two tables in a staging Bigtable instance with the two narrow and wide schemas detailed above.
After implementing and testing the validity of the two schemas, we removed the overhead associated with our computation, in particular the read/write accesses to other services (including GCS and Stackdriver logs) to only keep the “raw” read of the events from Bigtable and computation of the user profiles from the events. To run the tests, we built the profiles sequentially for each application profile and table schema several times, as running multiple tests in parallel could affect the performance observed from each test.
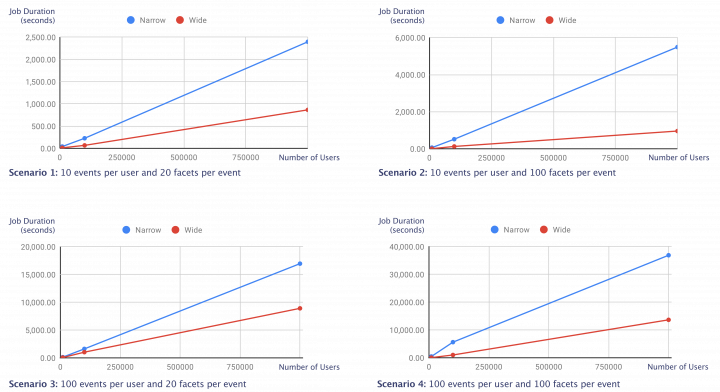
The results of the tests are shown in the plots below. As the number of events grows, the time it takes to read the events and compute the user profiles grows linearly for all schemas. As we can see on the plots, regardless of the scenario, the legacy schema has the worst performance and takes up to 16.6 hours (60,000 seconds) to compute a profile for 1,000,000 users with 100 events per day for 90 days. Clearly, the wide schema proved to have a huge impact on the user profile computation and allowed for non-negligible computational gains. The decision to migrate our legacy schema to the wide schema was an easy one to take.
We decided to migrate the narrow schema that we were using so far to the most efficient wide schema. To this end, we performed a three-step migration:
- We created a table with the wide schema and started to save events to both tables – the narrow and wide schema, respectively.
- After a week or so, we backfilled all the events from the 90-day retention period to the present time to the table with the wide schema.
- We moved the user profile computation from the narrow table to the table with the wide schema.
Caveats
The schema change had a positive impact on both app_id and user_token jobs, in particular on the client side, by reducing the bandwidth, CPU, and memory used in the individual pods when retrieving large numbers of events associated with user tokens. However, our solution comes with some caveats that we identified and weighed in our final choice to migrate to the wide schema.
Storage and computation. While the wide schema saves resources on the Bigtable client, it incurs storage and computational overhead on the Bigtable server. Since Bigtable applies compression on the row value, the compression is more effective with large row values. Storing the data with the wide schema increased the storage usage as compared to the legacy schema, but this was not an issue. Further, since the filtering of the rows is applied on the Bigtable server, it incurs additional computation overhead as compared to the narrow schema, which remains well below below the 80% recommended limit.
Number of qualifiers. The wide schema works because we made the assumption that the strategies defined by the customers will not cover all the possible facets required to filter the data, although we should set some limits on the maximum number of different facets. However, when all the possible facets are used in the strategy, the read performance is as good as the one with the narrow schema.
It’s all about trade-offs
The usage and access patterns to Bigtable should drive the schema design. In our case, we needed to optimize the read accesses since we only write the data once and need to access it several times, either through single user_token jobs or with app_id jobs. There are three levels of optimization.
The row key is the most important when it comes to reading and accessing the data stored in Bigtable. Since the rows are sorted lexicographically by row key, one needs to store related rows, or rows that will be read together and near each other in order to perform efficient scans of blocks of sorted keys. In our multi-tenant case, we prefix the row key with the application identifier. This improves the performance of jobs that need to sequentially scan the applications for admin tasks such as garbage collection and not just a specific user. Grouping keys by applications can lead to hotspotting for applications that are used a lot, but their data is also likely to be split on multiple computation nodes (since they generate a lot more data as compared to the other applications). Alternatively, large applications can be moved to dedicated tables in order to isolate them and hinder the performance of the rest of the applications.
The row schema addresses a trade-off between the computational and storage overhead on Bigtable server and the computational and bandwidth overhead on the client side. Having wider rows allows for better filtering despite increased overhead at the server side, while narrow rows defer the filtering on the client side, by requiring the retrieval of the full cell value.
Finally, since the row value is stored as byte[], one can optimize the row encoding by using a fast JSON marshaller, universal and complex Protocol Buffers, or custom formats such as Gob, depending on your needs.
We continue to plan for scale to accommodate ever-growing numbers of customers. We found that a small improvement in how we use Bigtable to process and store billions of events can allow us to scale our Personalization feature and take on the challenges of the coming months to improve the feature.