When allocators are hoarding your precious memory
While switching to the latest trendy framework or language has become somewhat of a cliché in the engineering world, there are times when upgrading is warranted and necessary. For our search engineering team, dedicated to maintaining the core engine features, this includes upgrading the operating system version to get the latest kernel or library features in order to quickly to accommodate our latest code releases.
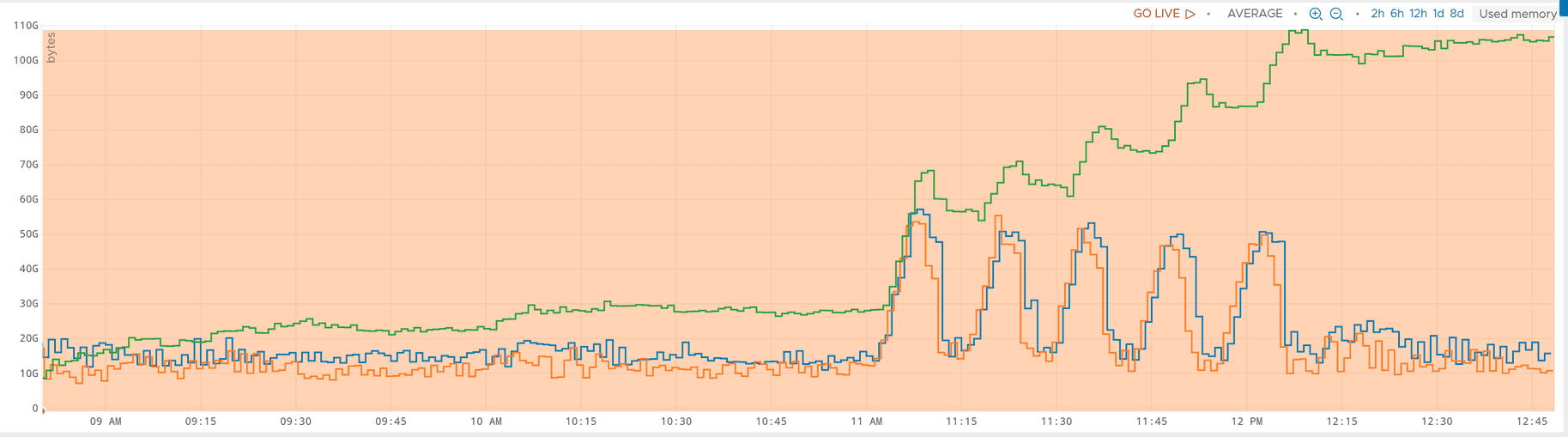
However, you always need to be prepared for unpleasant surprises when you are changing the version of a lot of components: kernel and its associated drivers, operating system’s C library, various libraries, but also possibly a lot of strategies, policies, default configuration settings that come with the operating system. One unpleasant surprise we had while upgrading was the overall memory allocation and consumption. A graph (courtesy of Wavefront metrics) being better than anything else, I’ll let you guess when the “green” server was upgraded to a higher operating system version below:
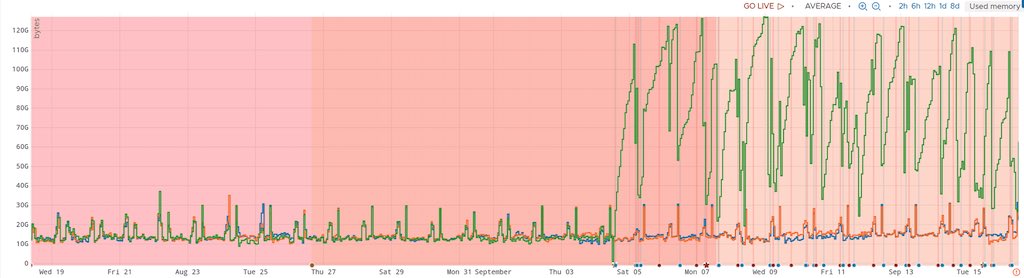
If you managed to spot the slight increase of memory consumption, yes, we moved from a consumption ranging between 10 and 30 GB of memory (with an average of 12) to a consumption between 30 and 120 GB of memory (with an average above 100). To be fair, consumption would be even higher, but we only have 128GB on this specific machine (which is more than enough, and is generally used as a big page cache), and the drops in memory consumption are the events when the process eating our precious memory is either forcibly being reloaded by us, or is forcibly being slaughtered by the angry kernel (which is kind of a bother, as it triggers a lot of alarms here and there). All in all, we have a problem. As a startup company, we are expected to fulfill the stereotypes of the 10x engineer, but this is probably not the 10x we are talking about.
Investigating excessive memory hoarding
The irony was not lost on us: we pushed for upgrading the system, and now we are responsible for the server taking up so much memory. Well, there was only one thing to do: we needed to understand why the upgrade had such a dramatic impact.
A leak?
The first idea that came to mind was to suspect some kind of a memory leak. But there’s a catch: only recent Linux versions have it. Can it be a memory leak triggered by a condition that we didn’t meet on the previous system? To validate this hypothesis, we usually leverage the incredibly powerful Linux perf profiler from Brendan Gregg. Every developer interested in performance should know this tool, and we highly recommend watching some of the presentations made by the master himself. A typical way to do this is to attach the running daemon, and look for unreleased memory (after 10 minutes) from time to time:
sudo memleak-bpfcc -a --older 600000 --top 10 -p 2095371 120
Unfortunately, we did not see any leaks — even when in the meantime the process ate a hundred gigabyte of our precious RAM. So this wasn’t a leak, but we were losing memory. The next logical suspect was the underlying memory allocator.
The greedy allocator, a memory hoarder
Okay, you might be confused, as we have several allocators here. As a developer, you probably heard about malloc, typically located in the C library (the glibc). Our process is using the default glibc allocator, which can be seen as some kind of a retailer for any size of memory allocations. But the glibc itself can’t allocate memory, only the kernel can. The kernel is the wholesaler, and it only sells large quantities. So the allocator will typically get large chunks of memory from the kernel, and split them on demand. When releasing memory, it will consolidate free regions, and will typically release large chunks by calling the kernel. But allocators can change their strategy. You may have several retailers, to accommodate multiple threads running inside a process. And each retailer can decide to retain some of the large memory chunks released for later reuse. Retailers can become greedy, and may refuse to release their stock. To validate this new hypothesis, we decided to play directly with the glibc allocator, by calling its very specific “garbage collector”:
MALLOC_TRIM(3) Linux Programmer's Manual MALLOC_TRIM(3)NAMEmalloc_trim - release free memory from the top of the heapSYNOPSIS#include <malloc.h>int malloc_trim(size_t pad);DESCRIPTIONThe malloc_trim() function attempts to release free memory at the topof the heap (by calling sbrk(2) with a suitable argument).The pad argument specifies the amount of free space to leave untrimmedat the top of the heap. If this argument is 0, only the minimum amountof memory is maintained at the top of the heap (i.e., one page orless). A nonzero argument can be used to maintain some trailing spaceat the top of the heap in order to allow future allocations to be madewithout having to extend the heap with sbrk(2).RETURN VALUEThe malloc_trim() function returns 1 if memory was actually released
A simple yet hacky solution is to attach to the process with a debugger (gdb -p pid), and manually call malloc_trim(0). The result speaks for itself:
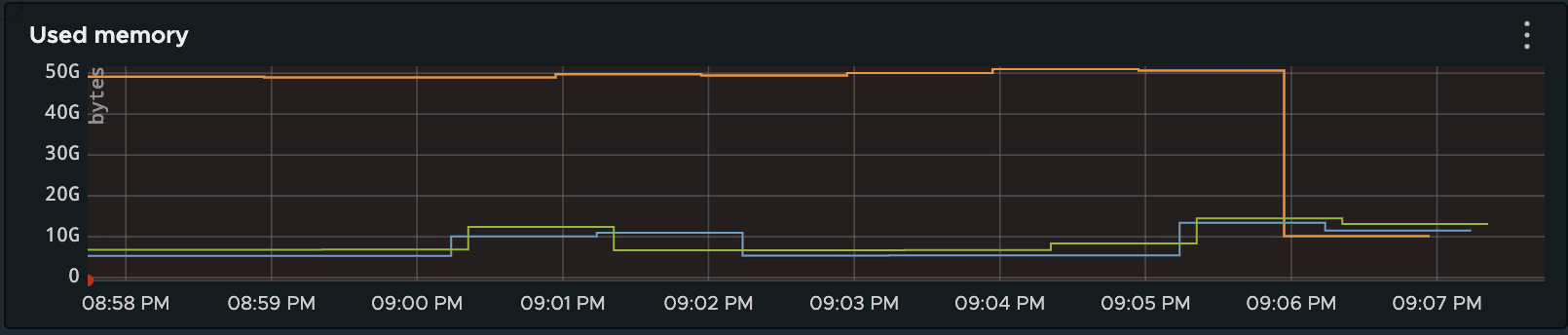
The orange is the upgraded server memory consumption, the two other curves are the previous operating system’s versions. The sudden drop at around 09:06 is the call to the malloc_trim function. To corner-case the problem, we also used another rather useful glibc-specific function, dumping some states of the allocator:
MALLOC_INFO(3) Linux Programmer's Manual MALLOC_INFO(3)NAMEmalloc_info - export malloc state to a streamSYNOPSIS#includeint malloc_info(int options, FILE *stream);DESCRIPTIONThe malloc_info() function exports an XML string that describes thecurrent state of the memory-allocation implementation in the caller.The string is printed on the file stream stream. The exported stringincludes information about all arenas (see malloc(3)).As currently implemented, options must be zero.RETURN VALUEOn success, malloc_info() returns 0; on error, it returns -1, witherrno set to indicate the cause.
Yes, here again, attach and directly use gdb:
(gdb) p fopen("/tmp/debug.xml", "wb")$1 = (_IO_FILE *) 0x55ad8b5544c0(gdb) p malloc_info(0, $1)$2 = 0(gdb) p fclose($1)$3 = 0(gdb)
The XML dump did provide interesting information. There are almost a hundred heaps (the “resellers”), and some of them show bothersome statistics:
<heap nr="87"><sizes>... ( skipped not so interesting part )<size from="542081" to="67108801" total="15462549676" count="444"/><unsorted from="113" to="113" total="113" count="1"/></sizes><total type="fast" count="0" size="0"/><total type="rest" count="901" size="15518065028"/><system type="current" size="15828295680"/><system type="max" size="16474275840"/><aspace type="total" size="15828295680"/><aspace type="mprotect" size="15828295680"/><aspace type="subheaps" size="241"/></heap>
The “rest” section appears to be free blocks, after a glance at glibc’s sources:
fprintf (fp,"<total type="fast" count="%zu" size="%zu"/>\n""<total type="rest" count="%zu" size="%zu"/>\n""<total type="mmap" count="%d" size="%zu"/>\n""<system type="current" size="%zu"/>\n""<system type="max" size="%zu"/>\n""<aspace type="total" size="%zu"/>\n""<aspace type="mprotect" size="%zu"/>\n""</malloc>\n",total_nfastblocks, total_fastavail, total_nblocks, total_avail,mp_.n_mmaps, mp_.mmapped_mem,total_system, total_max_system,total_aspace, total_aspace_mprotect);
and is accounting 901 blocks, for more than 15GB of memory. Overall statistics are consistent with what we saw:
<total type="fast" count="551" size="35024"/><total type="rest" count="511290" size="137157559274"/><total type="mmap" count="12" size="963153920"/><system type="current" size="139098812416"/><system type="max" size="197709660160"/><aspace type="total" size="139098812416"/><aspace type="mprotect" size="140098441216"/>
Yes, that’s 137GB of free memory not reclaimed by the system. Talk about being greedy!
Tuning the internals with glibc
At this stage, we reached out to the glibc mailing-list to raise the issue, and we’ll happily provide any information if this is confirmed to be an issue with the glibc allocator (at the time of writing this post, we have not learned anything new). In the meantime, we tried tuning the internals using the GLIBC_TUNABLES features (glibc.malloc.trim_threshold and glibc.malloc.mmap_threshold typically), unsuccessfully. We also tried to disable the newest features, such as the thread cache (glibc.malloc.tcache_count=0), but obviously the per-thread allocation cache was for small (hundreds of bytes at most) blocks. From here, we envisioned several options to move forward.
The (temporary) fix - the garbage collector
Calling malloc_trim regularly is a rather dirty temporary hack, but appears to be reasonably working, with runs sometimes taking several seconds to 5 minutes each:
{"periodMs": 300000,"elapsedMs": 1973,"message": "Purged memory successfully","rss.before": 57545375744,"rss.after": 20190265344,"rss.diff": -37355110400}
Notably, GC time seems to be linear with accumulated free space. Dividing the period by 10 also divides both reclaimed memory and spent time in GC by the same factor:
{"periodMs": 30000,"elapsedMs": 193,"message": "Purged memory successfully","rss.before": 19379798016,"rss.after": 15618609152,"rss.diff": -3761188864,}
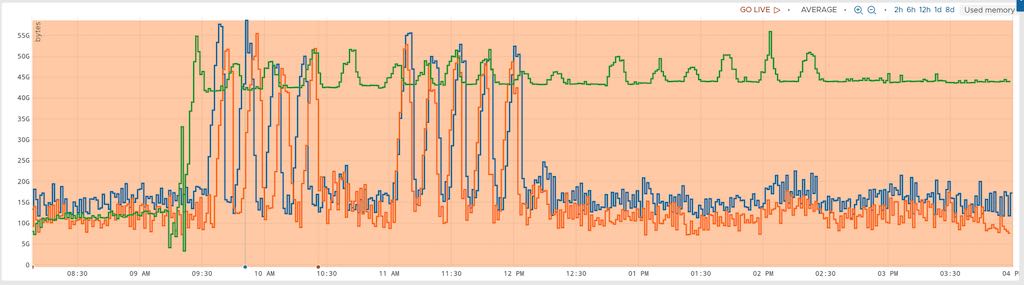
The impact of calling the GC is rather obvious on this graph:
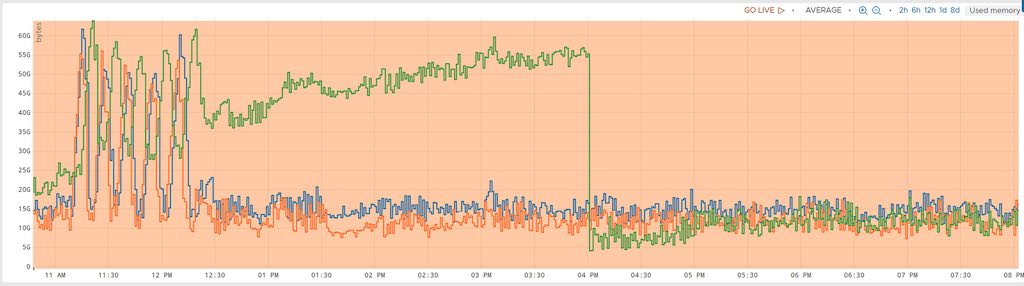
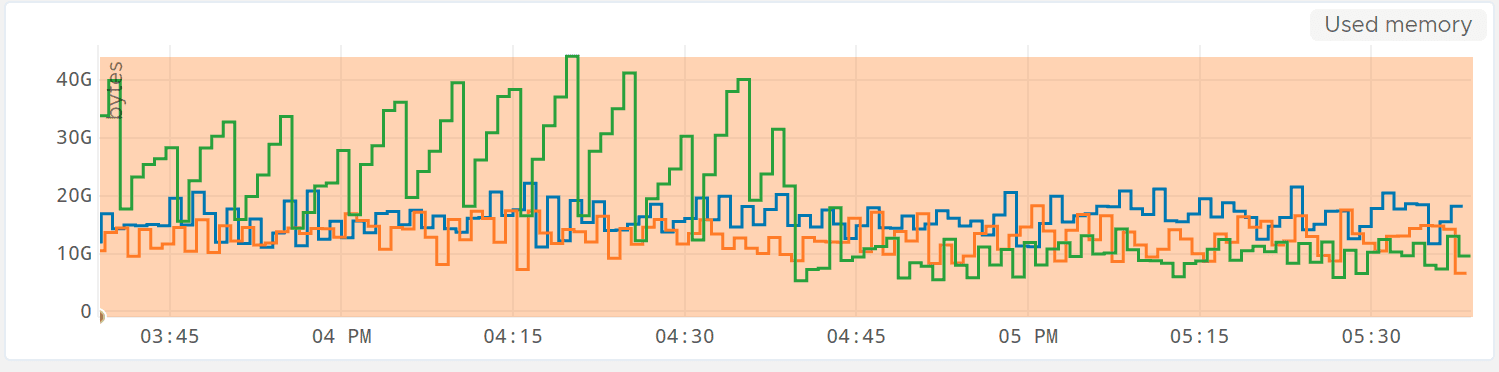
In green, the new glibc, in blue, the former version. The orange curve is the former glibc with a regular GC. The server embedding the new glibc slowly drifts, taking an increasing amount of space (almost 60GB here). At 4:00pm, the GC is started in the new (green) glibc code, and you see the memory consumption stats low. And the green curve below demonstrates the impact on changing the GC period from 5 minutes to 30 seconds:
Lastly, we also successfully tested an override of free that triggers trim operations when freeing a certain amount of memory:
#include#include#if (!__has_feature(address_sanitizer))static std::atomic freeSize = 0;static std::size_t freeSizeThreshold = 1_Gi;extern "C"{// Glibc "free" functionextern void __libc_free(void* ptr);void free(void* ptr){// If feature is enabledif (freeSizeThreshold != 0) {// Free block sizeconst size_t size = malloc_usable_size(ptr);// Increment freeSize and get the resultconst size_t totalSize = freeSize += size;// Trigger compactif (totalSize >= freeSizeThreshold) {// Reset now before trim.freeSize = 0;// Trimmalloc_trim(0);}}// Free pointer__libc_free(ptr);}};#endif
All those tests were executed on several clusters to confirm different workloads. What is the cost of the GC ? We did not see any negative impact in terms of CPU usage (and notably system CPU usage), and, looking at malloc_trim implementation, it appears each arena is locked separately and cleaned one by one, rather than having a “big lock” model:
int__malloc_trim (size_t s){int result = 0;if (__malloc_initialized < 0) ptmalloc_init (); mstate ar_ptr = &main_arena; do { __libc_lock_lock (ar_ptr->mutex);result |= mtrim (ar_ptr, s);__libc_lock_unlock (ar_ptr->mutex);ar_ptr = ar_ptr->next;}while (ar_ptr != &main_arena);return result;}
Dedicated memory allocator
Using a different allocator (which could include jemalloc or tcmalloc) is another interesting possibility. But moving to a totally different allocator code has some drawbacks. First, it requires a long validation, in semi-production and then production. Differences can be related with very specific allocation patterns we may have typically (and we really have strange ones sometimes, I can guarantee that). And because we are using a less common C++ library (libc++ from llvm), mixing both this less common case with an ever less common allocator could lead to totally new patterns in production. And by new, it means possible bugs nobody else saw before.
Investigating arenas and the memory management bug
The underlying bug is anything but obvious.
Arena leak
A bug filled in 2013, malloc/free can't give the memory back to kernel when main_arena is discontinuous, looks a bit like the issue we are experiencing, but this is nothing new in our systems, and despite having malloc_trim reclaiming memory in glibc 2.23, the order of magnitude of our current problem is totally unprecedented. This bug is however still pending, possibly only impacting corner-cases.
Number of arenas
Increase of arenas might be another possibility. We grew from 57 arenas in 2.23 to 96 arenas in 2.31, on the same hardware and environment. While this is a notable increase, here again, the order of magnitude is too wide to be the trigger. Alex Reece suggested on his blog post about Arena "leak" in glibc to reduce the number of arenas down to the number of cores through the glibc.malloc.arena_max tunable. This totally makes sense when your process doesn’t have more threads than cores (which is true in our case), and could in theory mitigate the wasted memory issue. In practice, unfortunately, it did not: reducing the number of arenas from 96 down to 12 still leaves the same issues:
Even reducing to 1 (that is, the main sbrk() arena), actually:
Arena threshold
Interestingly, each growing arena stops growing after a while, capping up to the maximum allocated memory in the process history. The free-but-not-released blocks can be huge (up to a gigabyte), which is rather surprising as those blocks are supposed to be served with mmap.
To be continued
We’ll continue playing with different scenarios, and ideally have a trivially reproducible case one day soon that could help fixing the root cause. In the meantime, we have a workaround (a kind of a GC thread) which is far from being perfect, but will allow us to move forward.
The takeaway
Upgrading operating systems and libraries has potential impact that are often overlooked. Limiting risks can include upgrading different components (such as upgrading the kernel, or linked libraries to the newest ones), one by one over a period of time, each for long enough to detect regressions (memory or CPU usage, changes of behavior, instability…). Upgrading more regularly is also another point that could have helped here (jumping two system releases at once is probably not the safest choice). Lastly, executing rolling upgrades, and looking at collected sets of metrics very closely should be a part of healthy production deployment procedures. We have certainly learned and will be implementing these lessons in our processes going forward.
Have questions or similar experiences? @algolia