Writing code that is testable, maintainable, usable
Writing code is hard. Writing maintainable code, harder.
For a software company relying on team work, or with code projects spanning many years, one often relevant metric of code quality is how maintainable (fixable, modifiable, easy refactoring) and extendable (re-usable, composable) it is; in other words, whether or not the code is usable and re-usable from a software engineering perspective.
We'll take a look at how to design usable code, and how testability and loose coupling techniques can make our code more maintainable. We’ll present ways to make our code composable and (re)usable.
Writing testable code
Testing code means subjecting it to controlled input to verify it produces the expected outputs, and exhibits the expected behavior.
There are lots of ways to test code; we’re going to focus on integration testing and unit testing.
We’ll see how complementary these kinds of testing can be in verifying the behavior of our code against both regular and edge cases (i.e., cases at the fringe of things that can happen).
Integration testing
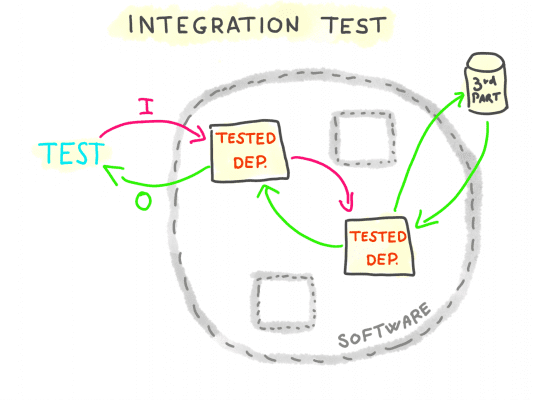
Integration testing is testing parts of the software in isolation, exposing them to real inputs and using real I/O systems.
It checks that parts of the software behave as expected when exposed to real I/O systems. Integration testing is used for regular use cases (the so-called “happy path”), because it’s usually hard to induce edge-case behaviors in real I/O systems (DB connections erros, corrupted data, filesystem failures, network timeouts).
Unit testing
This is testing parts of the software in isolation, controlling their inputs, and using dummy I/O systems and dependencies. It verifies their output and behavior when exposed to regular cases as well as edge-cases of the inputs and dependencies (slow dependency, corrupted dependency, erroring dependency, invalid inputs).
By “dependency” we mean everything that a piece of code does not own but uses (typically, other piece of code in the same software like services and modules).
Unit-testing a piece of code on regular as well as edge-cases requires a fine control over the dependencies it uses (API clients, db connections, mailer, logger, authorization layer, router).
In short, unit-testing detects issues occurring on edge-cases (i.e., at the fringe of things that can happen) in a way that integration and end-to-end testing cannot.
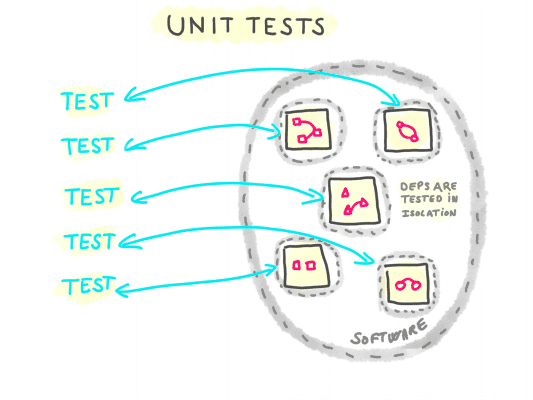
re-interpretation of the Martin Fowler’s UnitTest diagram
Of course, sometimes, the cases our software is exposed to in the wild are too many to completely test it; but even then, unit testing remains a valid tool to ensure that the edge-cases that are indeed identified are handled properly.
How to test your code to ensure that you test all code
Writing tests for unit and integration testing, requires the ability to:
- Run parts of the software independently
- We’re going to do that by isolating every concern in its scope
- Induce edge-cases in our code
- We’re going to do that by controlling dependencies behavior, using dependency mocking
- Substitute the implementation of a dependency with a dummy dependency
- We’re going to do that by injecting mocked dependencies
Single Responsibility Principle: Isolate parts of the software to run them independently
Usually, a software does more than one thing, and even a single feature might depend on other features.
Yet we need to isolate and test each feature, one at a time, because:
- Makes the setup of the test easier
- Makes it more obvious that we need to test all cases
- Helps pinpoint the reason for a failing test
To achieve the desired level of isolation, we apply the Single Responsibility Principle (SRP) to our code, stating that every part of our software should address one single concern.
The scope of a concern is contextual to the software; for instance, in most software sending emails, a mailer service is a single responsibility, addressing emails to a SMTP. But in the code of an emailing platform, the mailer may be spanning many concerns (SMTP, templating, security, permissions, rate limits)

Now that we have dependencies with clean-cut concerns, let’s see how we can select and initialize them adaptively in our code.
Writing edge case tests: Induce edge cases in our code
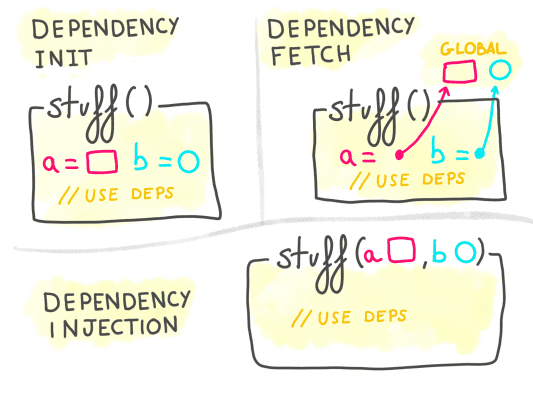
A traditional way for a piece of code to get a handle on its dependencies is to build or fetch them itself; for instance, a service responsible to query users on a JSON API that builds its own API client, or fetches it from a global singleton.
Passing initialized dependencies to a piece of code instead of letting it build or fetch them gives us the ability to control how dependencies are initialized.
The code loses control over its dependencies, and expects to receive them fully initialized.
This pattern is called “Inversion of Control” (IoC), or “Dependency Injection” (DI).
It’s a powerful principle in itself, but when it comes to testability, it takes a whole other dimension as we’re about to see in the next section.
Substitute the implementation of a dependency with a dummy dependency
We saw that injecting dependencies is a way to control their initialization (and in turn, their behavior) outside of the code that uses them.
Continuing our previous example of a dependency being a JSON API client, how would we go about testing our code using this API on its edge-cases (slow response, timeout, broken json, invalid response, …)?
We could rig the API client to artificially increase its latency and mangle the JSON returned by the server. However, it would also add a lot of “testing” code to the actual API client, with the threat of it being an issue for production usage or complicating debugging.
To solve this, we can use another implementation of the API client altogether, able to simulate regular and edge-cases: a mock implementation.
Mocking dependencies is a way to completely control the behavior they expose to the tested code, simulating all kinds of edge cases with reduced effort.
A mock looks exactly like the real thing on the outside (exposes the same methods), but is actually hollow, and will just produce the output we need for the test case (normal output, slow output, error, etc.)
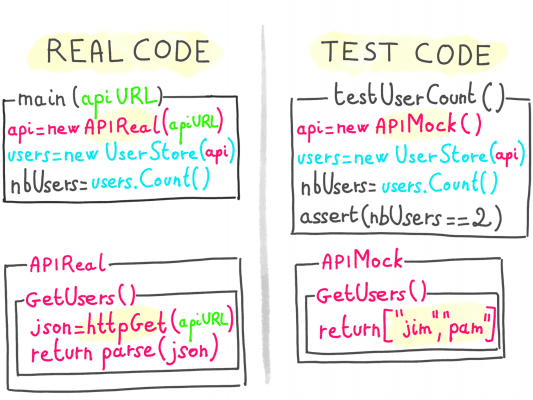
For a piece of code to accept a mock instead of the real thing, it should not expect to be injected with a concrete type, but rather with an abstraction representing the dependency.
This abstraction would focus on what the dependency is able to do (the signature of its methods), without preconception on how it’s implemented.
To achieve that in languages that support them, we usually use interfaces.
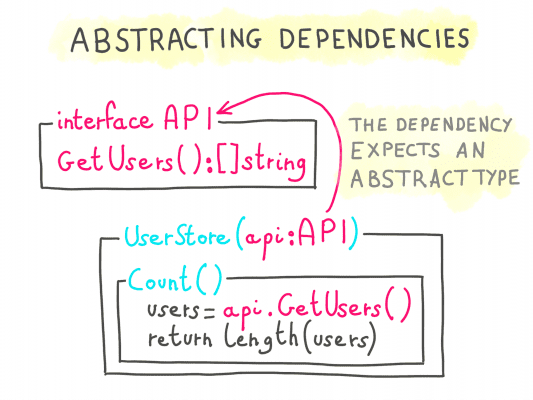
Interfaces abstract the implementations in the code, so that an implementation can be substituted with another one following the same interface.
Note: We’re using the term Interface as it’s broadly understood, but languages that don’t support interfaces or typings at the API level can apply this principle nevertheless by relying on Duck Typing.
Usability
“Before software can be reusable it first has to be usable.” – Ralph Johnson
— Programming Wisdom (@CodeWisdom) February 17, 2020, on Twitter
Ok, so now we’re testable. How do we make our code usable?
To reiterate, by usability of the code we mean:
- maintainability the ability to modify or fix the code with ease
- composability (or re-usability), the ability to extend the code by composing its parts with ease
Turns out, the very steps we took to write testable code actually made it more usable at the same time.
Code maintainability
Testability is a huge win for maintainability, as with tests we can verify that all tested cases still work after an update of the code base.
Single Responsibility Principle ensures that:
- the code is: partitioned in a way that maps precisely the concerns of our application;
- every concern is clearly identifiable, which increases discoverability of the codebase, and helps a lot during maintenance, too
- SRP makes our code Highly Cohesive and Lowly coupled.
Dependency injection ensures that the API of every part of the code explicits the dependencies it requires. The dependency graph of the software becomes visible through the APIs of the code, which helps with maintenance too.
Relying on abstract types (interfaces) to mock dependencies throughout our code produces cleaner, less coupled APIs. Combined with SRP, abstracted dependencies hide implementation details that would otherwise be leaked through a concrete type, which is what we want because:
- It follows the Interface Segregation Principle which loosens the coupling of our software
- It follows the Law of Demeter, stating that providing information usable without prior knowledge about its structure decreases the coupling of interacting parts
The loose coupling resulting from these principles limits the amount of code to be refactored when requirements change, easing maintainability.
Composability, (re-)usability
Composability: SRP and DI used in combination produce a software whose parts are composable, as features can be used independently of one another, which makes it easier to build new features into the software by leveraging existing code.
Reusability: loose coupling of the parts of our software (see above) enables the reusability or our code.
Mock “unmockable” dependencies
Some dependencies might not be easily mockable. There are many reasons for this; here are some of them, along with possible solutions.
Dependency exposes an “open” API, too broad to abstract
You might deal with methods expecting infinitely varying inputs that may result in an infinity of different outputs. For instance, a dependency that exposes a GetTodos(additionalSqlFilter: string) method.
Now imagine testing all possible values of additionalSqlFilter (spoiler: you can’t, because the dependency exposes an open API: SQL).
To solve this issue, we can encapsulate the dependency in an abstraction to expose a closed API with a limited number of methods.
To continue with our example, we would expose only the necessary predetermined use-cases for data fetching; for instance, GetAllTodos(done: boolean) and GetLateTodos(done: boolean).
This pattern is called Data Access Layer, and it’s a nice way to abstract database and other queryable APIs interactions in a testable way.
Dependency exposes many different concerns, making it hard to abstract
It’s often the case with a 3rd party dependency that they provide an API exposing different concerns for different uses.
Using them as concrete types in your code, complexifies the tests by making them mock more than might be strictly necessary, for it’s very likely that the tested pieces of code don’t use at once all the concerns exposed by the dependency.
SRP tells us the solution is to keep every dependency focused on a single domain; but how to achieve this on a 3rd party dependency, for which we don’t own the API?
Let’s use the Algolia API client as an example. If what your software uses of the API client is just its Search functionality, you might want to abstract the client behind an interface exposing only a “Search” method; doing so will have some nice side effects:
- The tests will have the guarantee that the tested code will never use another method than the “Search” one (as long as we don’t willingly update the interface) on the API client, reducing the required test setup
- It will be clear that we’re using the API client only to search, if just on the naming of the interface (something like SearchClient would fit our use case)
If in turn we need to add index manipulation to the same software, it’s likely that the “Search” and “Index” concerns of the application are going to be used in different contexts. We might want them to wrap the same Algolia API Client under another interface IndexerClient containing only the relevant “Index” manipulation methods.
This principle is called the Interface Segregation Principle.
Isn’t this SOLID?
Yes! Some SOLID principles are the same as the ones presented in this article.
SOLID however puts the emphasis for these principles on Object Oriented Programming (OOP) — for instance, the Open-closed Principle.
I believe that one can also embrace SRP, DI, Abstraction and Mocking (or a subset of them) regardless of whether the language is OOP or not.
Also,
It’s about controlling the code
Software development should always include designing code for testability, to force us to finely control its behavior. It turns out this is exactly what we need to make our code (re)usable in the first place.
If you have any questions or observations about any of the above topics, please don’t hesitate to ping me: I’m @jeromeschneider on Twitter.