Inside Algolia Engine 7 – Better relevance with dedup
One of the most unique and most-used features of Algolia is the Distinct feature: it enables developers to deduplicate records on-the-fly at query time based on one specific attribute. We introduced this feature three years ago, opening up a broad range of new use cases like the deduplication of product variants - a must-have for any eCommerce search. It has also considerably changed the way we recommend handling big documents like PDFs or web pages (we recommend splitting each document into several records).
This post highlights the advantages of this feature and the different challenges it represents in term of implementation.
Document search: state of the art and limitations
Searching inside large documents is probably the oldest challenge of information retrieval. It was inspired from the index at the end of books and gave the birth to an entire sub-genre of statistics. Among those methods, tf-idf and BM25 are the two most popular. They are very effective for ranking documents, but they don't handle false positives well - they push them to the bottom of the results.
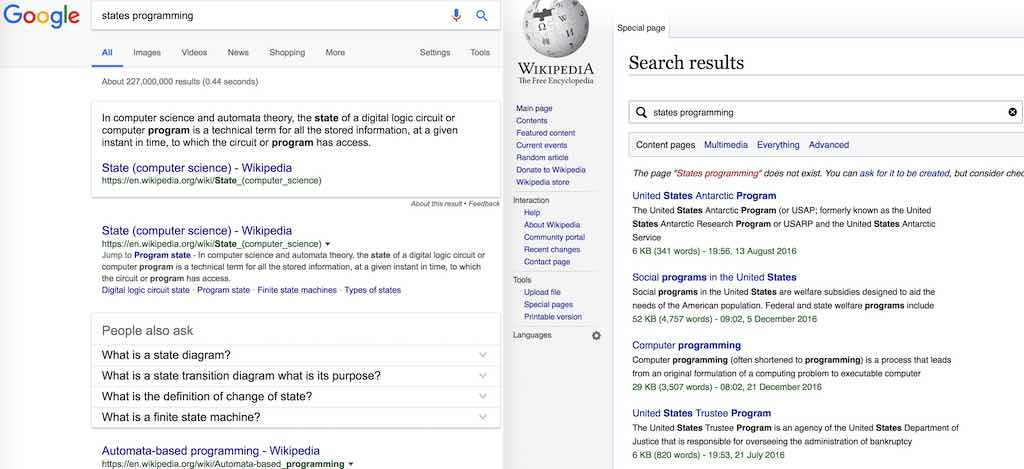
To illustrate this problem, you can perform the "states programming" query on Google and Wikipedia. According to Google Trends, this query is as popular as the Rust programming language and seems to correspond to developers that search how to develop an algorithm with a state. The same query on Wikipedia is unfortunately not very relevant! The first issue probably comes from a stemming algorithm or a synonym that considers "program" as the same than "programming." In Algolia, you can have an expansion of singular/plural without polluting results with stemming by using the ignorePlurals feature, which is based on a linguistic lemmatizer.
That said, even if you scroll through the first 1000 hits of Wikipedia search, you won't find the article which appears first in Google. There are hundreds of articles that contain both the word "states" and "programming." Even the "United States" page contains both terms and one is in the title! In this case, tf-idf and BM25 are not the most useful ranking criteria. The position of the two query terms in the document is more important, in addition to their relative distance (finding them close together is always better).
Why do we split large documents
One of the best ways to avoid such relevance problems is to split big pages into several records - for example, you could create one record per section of the Wikipedia page. If a Wikipedia article were to have 4 main sections, we could create 4 different records, with the same article title, but different body content.
For example, instead of the following big record with the four sections embedded:
We could have 5 different records, one for the main one and one per section. All those records will share the same source attribute that we will use to indicate the engine that they are all component of the same article:
We can use this same approach for technical documentation, as there are often just a few long pages in order to improve the developer experience: scrolling is better than loading new pages! This is exactly why we have decided to split pages into several records in our DocSearch project; you can learn more about our approach in this blog post.
It might sound counter-intuitive, but the problem is even more visible when your data set is smaller! While the problem is only visible on well-selected queries on the Wikipedia use case, it becomes very apparent when you search inside a website with less content. You have a high probability of having false positives in your search that will frustrate for your users.
The need for deduplication
Splitting a page into several records is usually easy as you can use the formatting as a way to split. The problem with several records per document is that you will introduce duplicates in your search results. For example, all paragraphs of the United States Wikipedia article will match for the "United States" query. In this case, you would like to keep only the best match and avoid duplicates in the search results.
This is where the distinct feature comes to play! You just have to introduce one attribute with the same value for all records of the same source (typically an ID of the document) and declare it as the attributeForDistinct in your index setting. At query time, only the best match for each value of the attribute for distinct will be kept, all the other records will be removed to avoid any duplicate.
If we split the United States Wikipedia article by section and subsections, it would generate 39 records. You can find the first four records on this gist:
This split by section reduces a lot the probability of noise on large articles. It avoids the query "Etymology Indigenous" to match this article (which would typically match because there is a section called "Etymology" and another one called "Indigenous and European contact"). To improve the relevance, we have also divided the records into three different types that we order from the most important to the less important via the recordTypeScore attribute:
- "main", this is the first section of the article, including the title and synonyms (score of 3)
- "section": those are the main sections of the article (score of 2)
- "subsection": subdivision inside the sections of the article (score of 1)
The recordTypeScore attribute will be used in the ranking to give more importance to the "main" records than the "section" and "subsection".
Another good property of this split is that it allows linking to the right section of the page when you click on the search result. For example, if you search for "united states Settlements", you will be able to open the United States page with the anchor text stored in the record.
Here is the list of the four Algolia settings we applied on this index:
You can set those settings via the setSettings API call or directly on the dashboard:
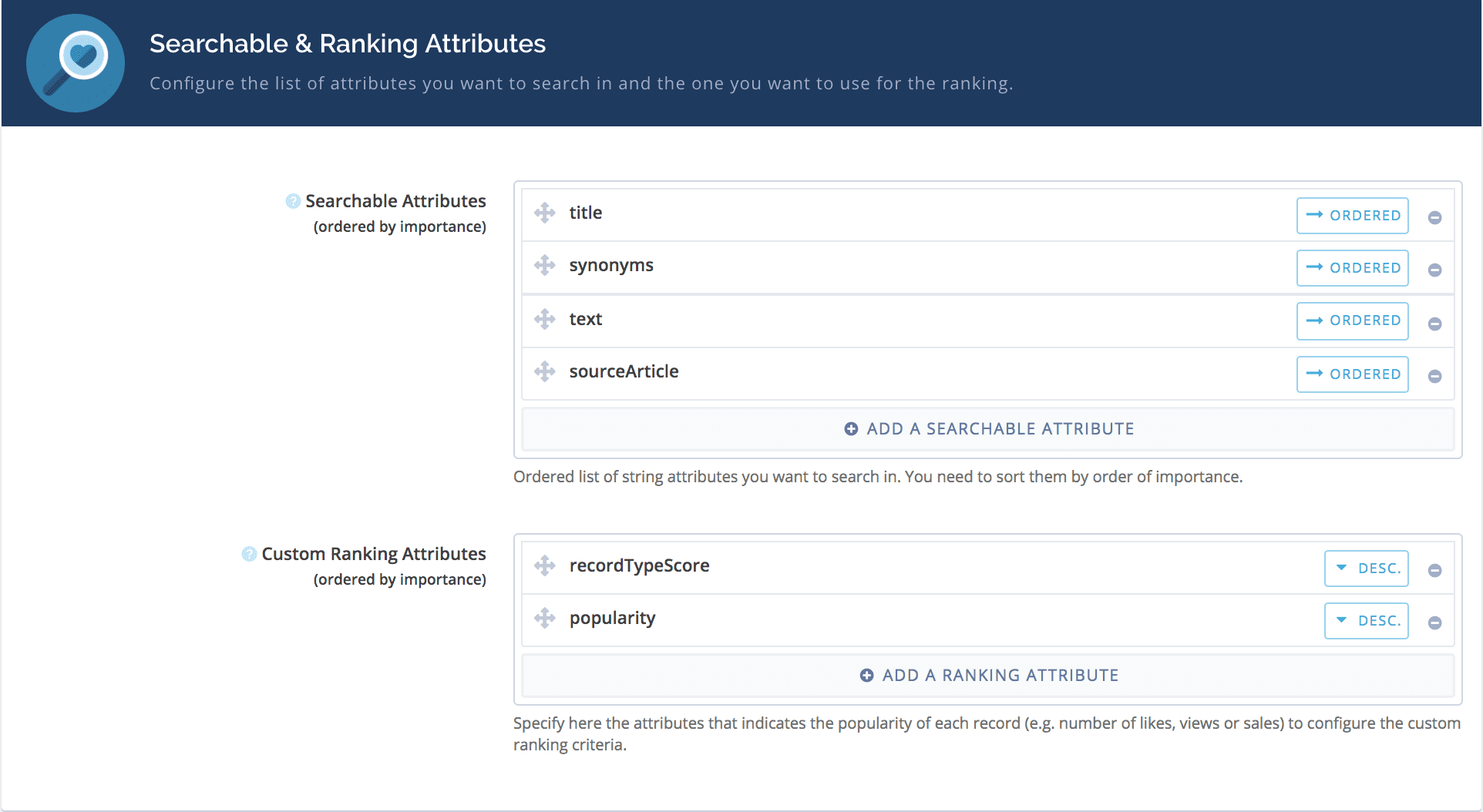
- searchableAttributes and customRanking can be configured in the Ranking tab
- ignorePlurals can also be configured in the Ranking tab. For the moment you can only enable it for all languages in the dashboard (setting it to true), we will improve this setting to let you configure also the language.
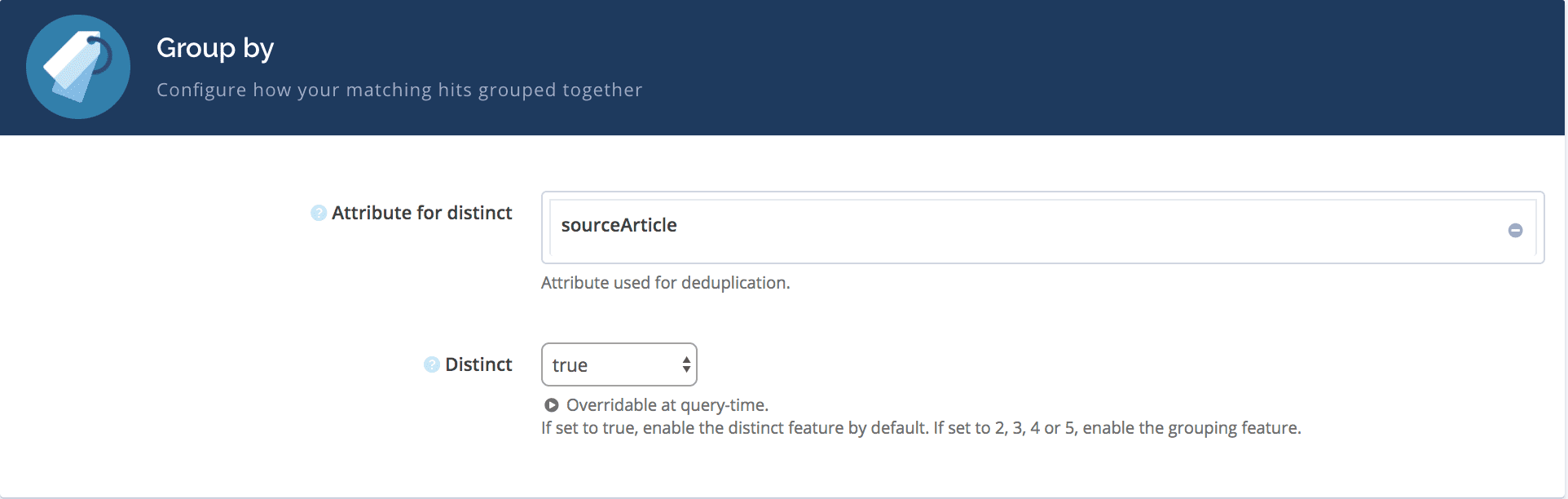
- attributesForDistinct can be configured in the Display tab of the dashboard:
Each of those settings is important for the relevance:
- The customRanking uses the recordTypeScore to give importance to the main chapter in the case of equality on the textual relevance. In case of equality, we use the popularity attribute which represents the number of backlinks inside Wikipedia to this article (all records of the article keep the same popularity)
- The order of attributes in searchableAttributes gives the following decreasing importance for the matching attributes, title > text > synonyms > sourceArticle
- The attributeForDistinct is applied on the name of the article, only the best elements will be displayed for each matched articles
- We set ignorePlurals to "en" to consider all singular/plurals form of English as identical without introducing any noise (you can also set this setting at query time if you have a search in a different language using the same index)
With those settings, you can easily request a set of results without duplicates with the query parameter distinct=true. You can go even further by requesting several hits per deduplication key. You can, for example, pass distinct=3 in your query to retrieve up to three results per distinct key - this feature is usually known as grouping.
Keeping several records per distinct key
Search engines are also used for navigation or criteria-based search due to the fact that those queries are cheaper than on a regular database. Keeping several records per distinct key makes it easy to bring a different display to search.
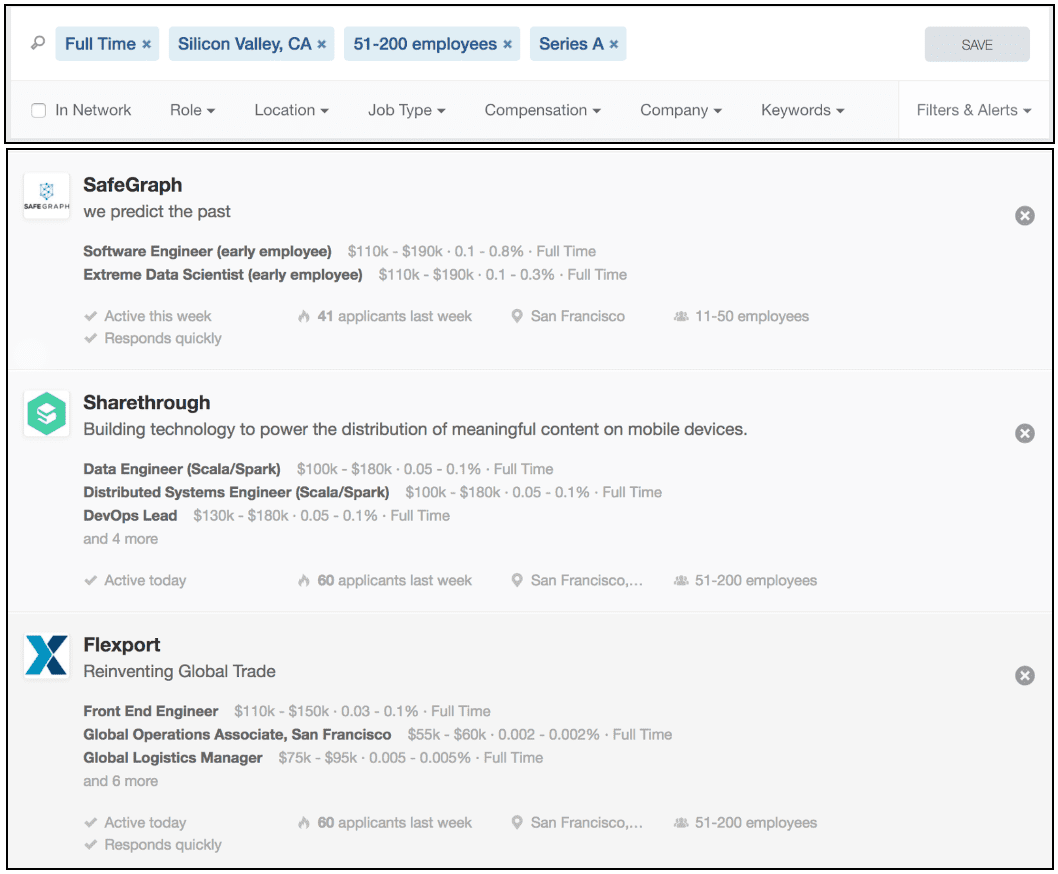
For example, if you want to build a list of job offers, you will probably let the user search via different criteria like the role, location, job type, etc - but you might also want to aggregate the search results per company instead of having each job display company information. This is what AngelList is doing when you search for a job on their platform. They display companies along with the three best job offers, this type of display can be built very quickly by:
- Having one record per job offer with an attribute containing the company ID
- Configuring the company ID attribute as attributeForDistinct in the index settings
- Passing distinct=3 in your query
With those three simple actions, you can build an interface like AngelList below (Note that SafeGraph has only two job offers that match the criteria, the value three is the upper-bound limit on the number of records we want per distinct key). Some customers also implement a "Show more" button on each company that allows to display all offers for this company. To implement it, you have just to filter on the company name and specify distinct=false on the query to retrieve all offers of this company.
The Impact of Distinct on faceting
Faceting can very quickly become a headache when distinct is enabled. Let's illustrate the problem with a very simple example containing two records sharing the same distinct key.
The first record contains the facet values "A" and "B" and the second record contains the facet values "B" and "C".
Let's imagine that you have a query that retrieves both records and that faceting and distinct is enabled in your query. You can imagine three different behaviors in this case:
- Computing the faceting before the deduplication (using distinct). In that case, the possible facet values will be "A=1", "B=2" and "C=1". All categories are retrieved but the count won't fit what you have on screen.
- Computing the faceting after deduplication (distinct). In this case, the result would be "A=1", "B=1" OR "B=1", "C=1" depending on the best matching record. In both cases, the result is not what you expect.
- Applying deduplication independently for each facet value. In this case, we would have A=1, B=1 and C=1 (for each facet value, we need to look at all distinct key and perform a deduplication at this level).
The third behavior is the holy grail as the result of each facet count would be perfect. Unfortunately, the computation cost is insane and doesn't scale as it directly depends on the number of facet values which match. In practice, it's impossible to compute it in real time.
Let's look at the advantages and drawbacks of the two approaches which can be computed for each query in a reasonable time:
- Computing the faceting before the deduplication: all retrieved facets are valid but the problem is obviously the counts are misleading because they include the duplicates. That said, this approach works very well if you do not want to display the count, it handle any case including the fact you can have different facets in the records that share the same distinct key.
- Computing the faceting after the deduplication: this approach works well when you use distinct=1 and all records with the same distinct key share the same facet values, which correspond exactly to the use case of splitting big documents. In other use cases, the results will be disturbing for users as some facet values can appear/disappear depending on the record which is kept after deduplication.
In other words, there is no perfect solution solving all problems. This is why we have decided to implement both approaches but as the deduplication can be misleading and cause weird effect, we have decided to use the faceting before the deduplication as the standard behavior. We have a query parameter called facetingAfterDistinct=true that can be added to your query when you are splitting some big records. In this case, you have a perfect result because the facets are identical in all records sharing the same distinct key.
Great features take time
We introduced the distinct feature in December 2013 and have improved it significantly in July 2015 by adding the support of distinct=N in the engine. The different faceting strategies have been a long-standing challenge and it took us a lot of time to find the best approach. The query parameter facetingAfterDistinct=true has been beta tested with real users for a few months before becoming public in December 2016.
This feature opened a lot of possibilities for our users and allowed a better indexing of big records that later gave the birth to our DocSearch project.
Next readings
We hope this post gives you some insight into the inner workings of our engine and how we got where we are today. As always, we would love your feedback. Definitely leave us a comment if you have any questions or ideas for the next blog in the series.
I look forward to reading your thoughts and comments on this post and continuing to explain how our engine is implemented internally. Transparency is part of our DNA! :)
We recommend reading the other posts of this series:
- Part 1 – indexing vs. search
- Part 2 – the indexing challenge of instant search
- Part 3 – query processing
- Part 4 – Textual Relevance
- Part 5 – Highlighting, a Cornerstone of Search UX
- Part 6 – Handling Synonyms the Right Way
- Part 7 – Better relevance via dedup at query time
- Part 8 – Handling Advanced Search Use Cases
Other links: