Inside Algolia Engine 8 — UI/UX for advanced search
Building great search UX is one of the hardest problems in engineering, even for companies that have a large team working exclusively on search.
There are three essential hurdles to clear:
- engine performance
- interface intuitiveness
- result relevance
We’ve addressed search performance in several of the previous articles of this series; this article will focus on the link between user interface and relevance. It will cover a wide range of use cases — from common to very specific. If users complain that they cannot find what they are searching for quickly, it is probably caused by a mix of non-intuitive interface and poor relevance; this is why it is important always to consider them together.
Providing good relevance for the most common cases
When people are searching for something very general like a company name on LinkedIn or a person on Twitter, you should make sure you are using a notion of popularity on the results: a result with more followers has more chance to be what the users are searching for. Solving this problem has been our primary focus at Algolia from day one. We have addressed this by developing a configurable but easy to understand ranking algorithm where developers have full control of their search configuration. You can configure the popularity via Custom Ranking, make sure you can address a complex problem like typosquatting, promote some featured items, etc.
There is an endless way to configure the ranking, depending on the use case. We could even help Twitter solve their search issues :), as you can see in the following example:
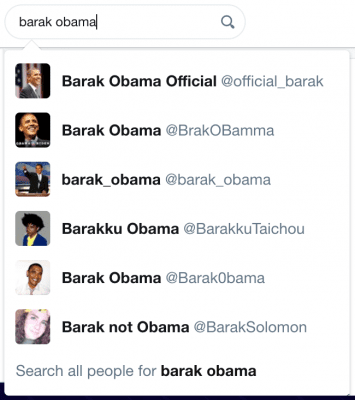
Providing good relevance for advanced search use cases
Solving advanced search use cases is an entirely different problem where you need to let the user refine search results via filters. We will cover in this section the three main approaches that are used to facilitate an advanced search.
Use of faceting
Faceting is probably the most standard way to address advanced use cases. The principle is to let the user filter the results based on categories to reduce the size of the results set and remove all false positives or ambiguity. This feature is used in a wide variety of use cases, and there are a lot of different ways to present faceting results, as you can see in our faceting documentation.
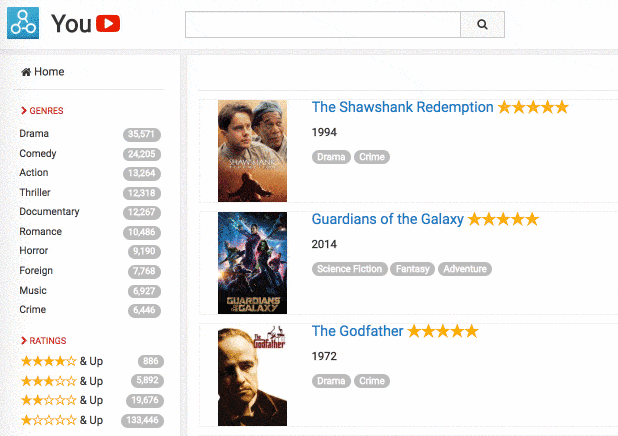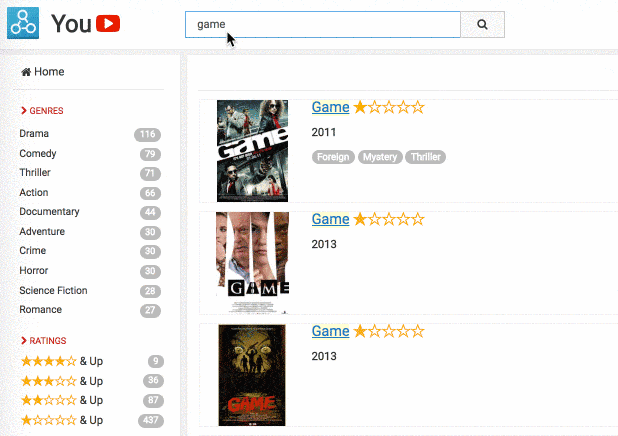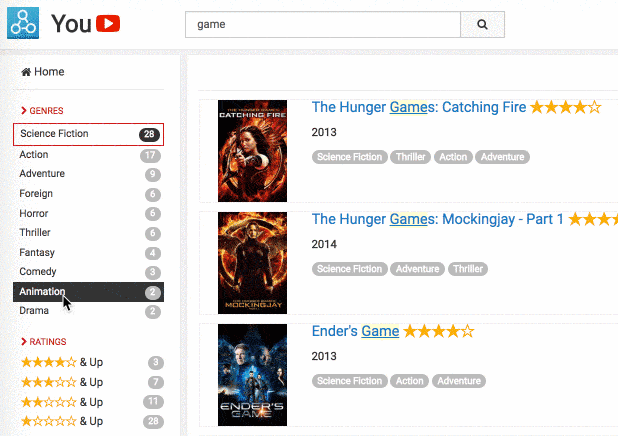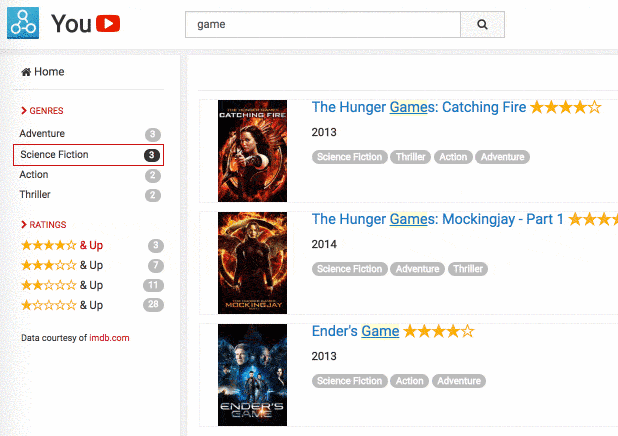
That said, faceting is not the perfect solution in all situations as two significant concerns can hurt your relevance:
It requires homogenous data: you need to have the same categories inside all your records to have a good UX. If this is not the case, you might have duplicates in your faceting results that will lead to users not finding their record while filtering.
The category that the user wants is hidden: when the number of categories to display is large, you won't be able to show all of them, and you might miss the one that the user wants. It will be a challenge to satisfy this user, who will probably just consider your search not good enough.
Search in faceting results
To fix the second problem—faceting not visibly proposing the category that the user is looking for—you can offer users a search for facet values. This means that the full range of categories does not even have to be displayed. Rather, you can offer the most relevant or meaningful categories, and let the user search for the rest. You can find this type of experience on LinkedIn: you can filter on locations when you are looking for a person or a company. LinkedIn proposes you to search for a particular location that is not listed in the selected facet values, which allows being very granular in your search.
The only problem that you might have on Linkedin is that this search is not contextual. You are searching inside all locations but without applying the current textual query and filters. Let’s say that you are looking for a Director of Marketing job in Buenos Aires but that there aren’t any available on LinkedIn. After you’ve searched for the job title, LinkedIn allows you to refine your search and select “Greater Buenos Aires” in the location facet value search, although this will not return any results. This is frustrating as you’d naturally expect not to be offered filters that will lead you nowhere.
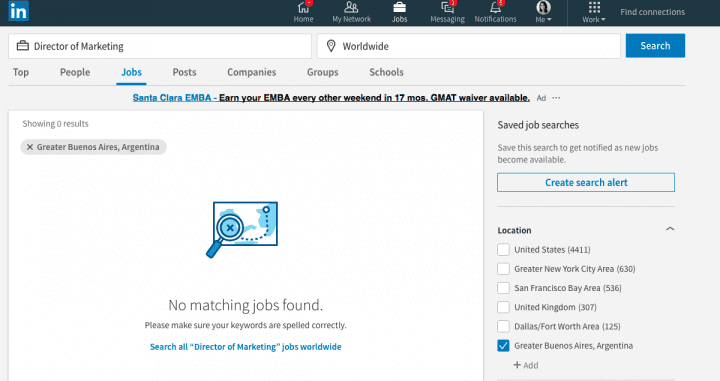
Implementing a search in faceting results while applying the contextual query is very complex, and this is probably the reason why LinkedIn preferred to implement a degraded version. A better search experience is our primary motivation at Algolia, which is why, a few months ago, we released a feature called search for facet values that allows you to develop this type of experience in minutes while applying the contextual query. Here is an example of an Algolia search in the brand value in an e-commerce context.
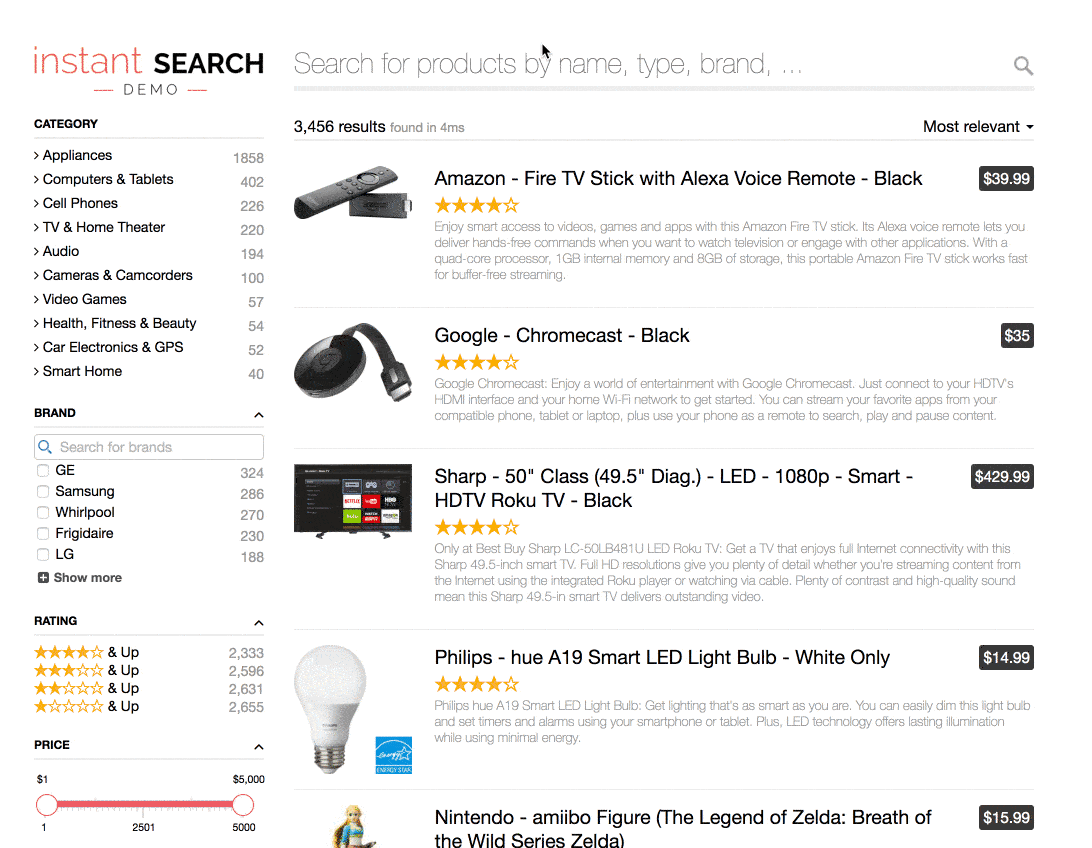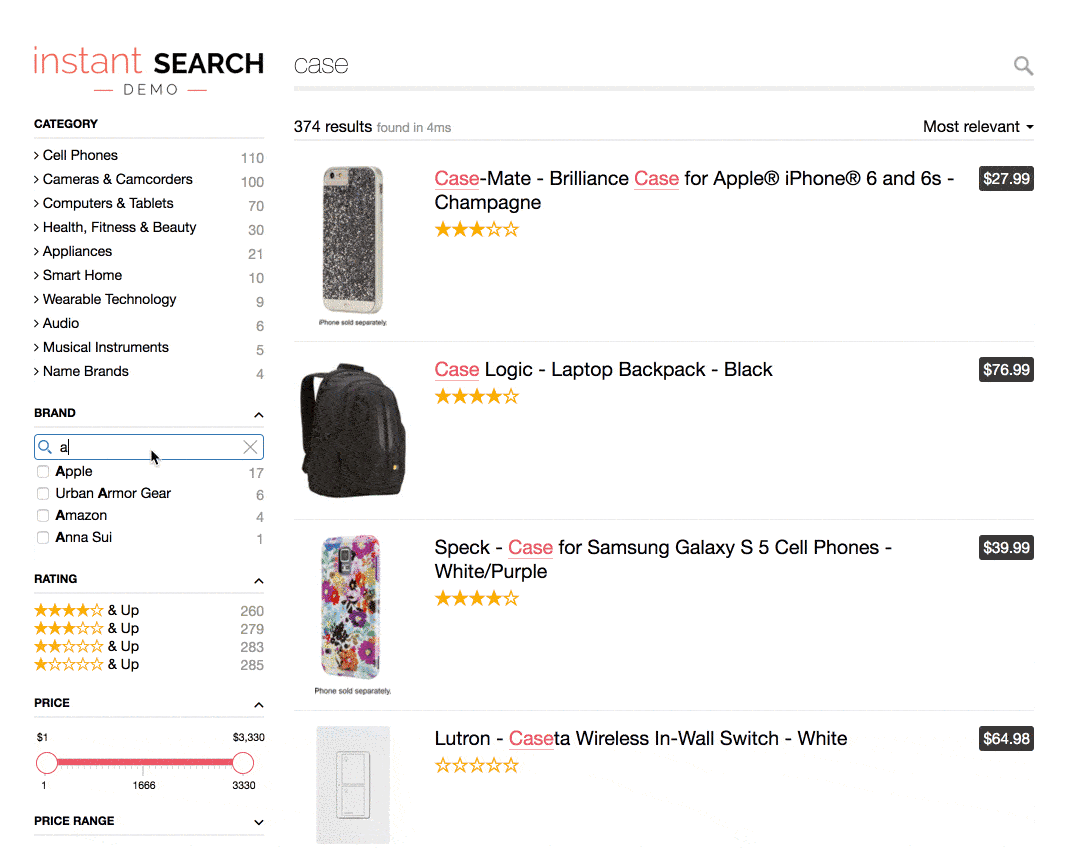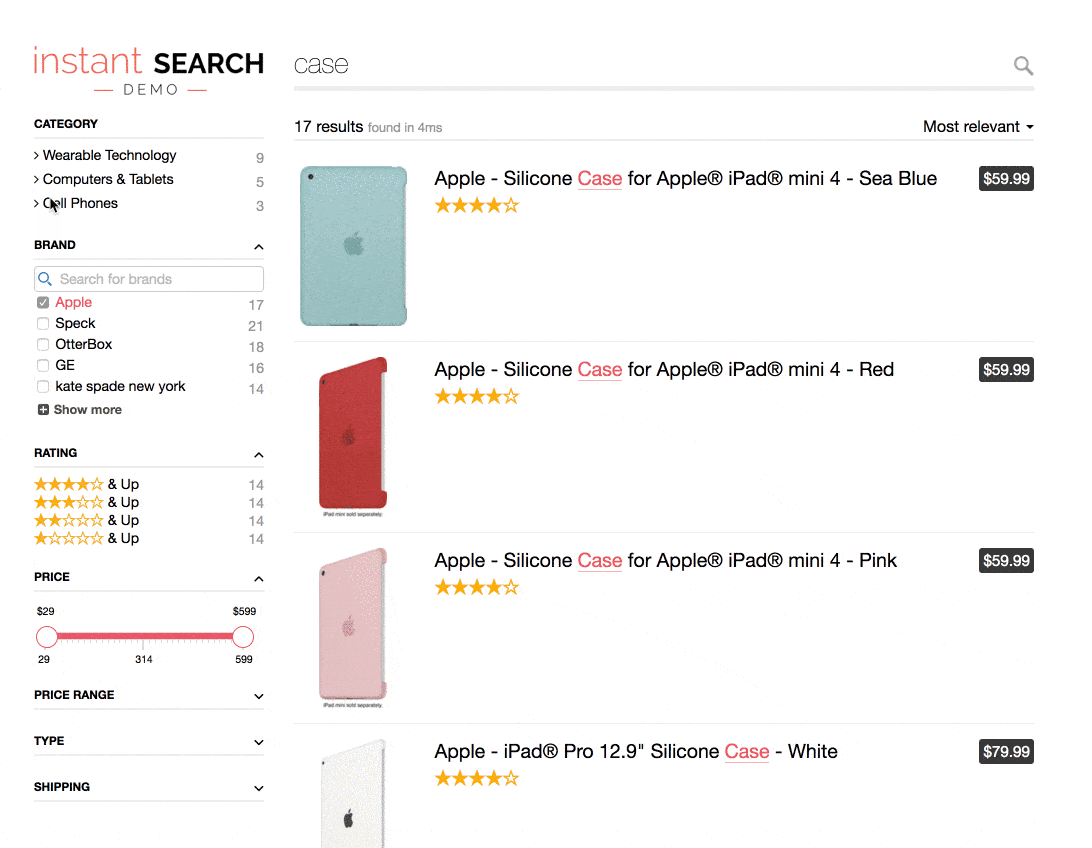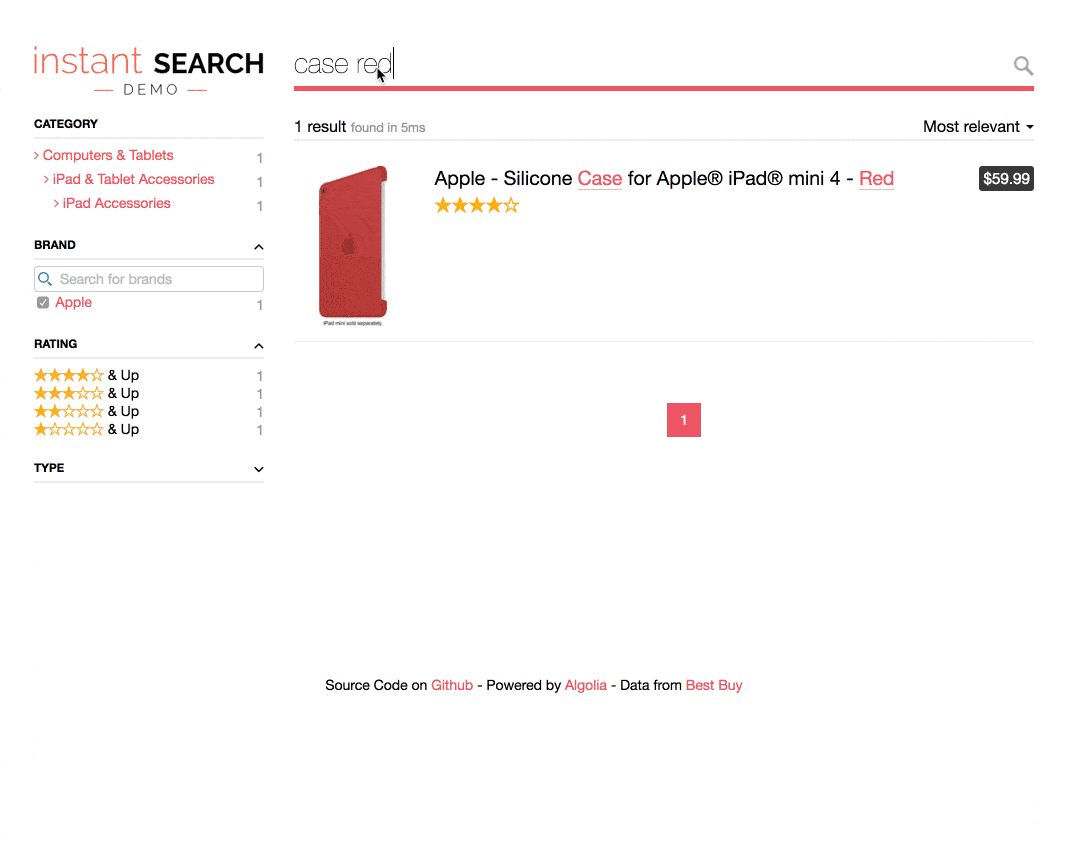
As you can see, the search is completely contextual: all filters/refinements are related and inclusive of one another. You can find more documentation about how to use it in our developer documentation.
Advanced query syntax
Search for facet values is very useful when you are looking to expose an advanced search to your user without burdening them with a learning curve, which is mandatory for a consumer product. If you are working on a business product that people use every day, you might want to expose them an advanced syntax inside the search box like Slack does.
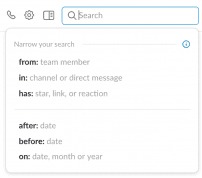 | 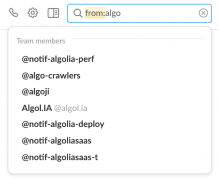 |
In practice, proposing such an experience requires the same feature as searching for facet values. It is just a different way to expose the same feature. The goal of this display is to let your advanced users directly perform their advanced query via the keyword and minimize the number of steps they will need to search for their content. You can implement such interface easily with our search for facet values feature. We will release a guide soon to help you through the implementation.
The implementation
We described in the previous sections how the search for facet values feature is useful for implementing an advanced search interface. We will now focus on the implementation to discover how this feature works internally.
I am sure you will think this type of search simply requires a change in the way we perform the query, like rewriting the query to specify which attribute we will target. But in practice, this is a significant change as we do not return records but rather highlighted facets with counts.
Let's take a simple example of a professional social network like LinkedIn to illustrate the implementation. We will take simple records containing only four attributes. Those attributes will contain a string and will all be configured as attributes for faceting:
- The name of the person
- Their title
- The company where they work
- The location of the company
Here is an example of such a record:
At first sight, this seems like a simple problem to solve for any search engine. Let’s look at what you need:If a user performs the query ”Twilio", they will retrieve hundreds of Twilio employees. Let's say the user wants to sell Twilio a service in San Francisco and wants to see all the Director titles to find the closest one to their service (this is, of course, a purely fictional use case :)).
The profiles need to work for Twilio, so we can restrict the search on “Twilio” to the “Company” field.
They need to be a Director, so you can restrict the search on “Director” to the “Title” field.
If multiple people have the same title, you want to see the title only once, so you need to deduplicate the results. To achieve this, you can use a facet on the attribute “Title”, and display the facet values returned.
In theory, this search should provide the results that you want, but in practice, it’s more complex than that:
People often have multiple job titles in their profiles. And if someone has both “Director of Sales” and “Account Executive” listed as a job title, this query strategy will mention both job titles in the list (because the query relies on faceting). Do you really want to see “Account executive” in the list of results for the query “Twilio Director”?
Since we’re displaying facet values, and not search results, we cannot highlight the words that match the query. It’s always better to have highlighting, particularly when people type something with typos (Diretcor), or if you search at each keystroke (Direc).
It creates a complex UI/UX, because users will need to specify that Twilio should only be searched in Companies, instead of allowing them to search Twilio in all fields (which would also potentially improve the relevance, on top of reducing the complexity).
There is a better solution: search directly in facet values while providing the context of the query. Let’s see how we can do this by using the “search for facet values” feature on the facet “Title”:
This query will be applied in two steps:
First, it will retrieve only the results containing the word Twilio in one of the searchable attributes. From this list, it will extract all of the values for the facet Title (i.e., all of the jobs titles listed in every profile that contain the word Twilio).
Then, in this filtered list of job titles, it’ll search for the ones that contain “Director”. This allows us to only retrieve relevant results, by using all of the regular search features (typo-tolerance, highlighting, prefix-search, ranking…). The result is the list of all the Twilio job titles containing “Director”, deduplicated and ordered by count — exactly what we were looking for.
In other words, this feature requires a two-step process that is only doable efficiently when implemented at the heart of the engine.
Evolutions
The release of this feature enabled all our existing users to build a great advanced search interface quickly. We, of course, do not plan to stop here and are already thinking about the next evolutions of the feature. For the moment, the ranking of results is pretty basic and is only using the frequency of facets, which means you can have a result with typo first. We plan to improve the feature by providing a different way to rank the results.
Next readings
We hope this post gives you some insight into the inner workings of our engine and how we got where we are today. As always, we would love your feedback. Definitely leave us a comment if you have any questions or ideas for the next blog in the series.
I look forward to reading your thoughts and comments on this post and continuing to explain how our engine is implemented internally. Transparency is part of our DNA! :)
We recommend reading the other posts of this series:
- Part 1 – indexing vs. search
- Part 2 – the indexing challenge of instant search
- Part 3 – query processing
- Part 4 – Textual Relevance
- Part 5 – Highlighting, a Cornerstone of Search UX
- Part 6 – Handling Synonyms the Right Way
- Part 7 – Better relevance via dedup at query time
- Part 8 – Handling Advanced Search Use Cases
Other links: